We benchmarked our semantic cache against Redis's. Here is what we found.
BetterDB vs RedisVL's SemanticCache on two public datasets, nine thresholds, and three configuration modes. Quality is at parity. First-query latency is at parity. On repeated queries BetterDB is 7x faster thanks to built-in embedding caching. Valkey and Redis 8 are indistinguishable. Full methodology and raw numbers included.
When we started building BetterDB's semantic cache, the obvious question was: how does it stack up against what is already out there? Specifically against RedisVL's SemanticCache class - the dedicated LLM-response cache shipped inside Redis Inc.'s open-source Python toolkit - which is the closest architectural peer to what we ship and what most developers reach for when they need a Redis-backed semantic cache.
So we built a benchmark, ran it honestly, and are publishing everything - including the parts where we are at parity rather than ahead.
Why RedisVL's SemanticCache is the right peer
Before the results, a word on peer selection. RedisVL is an AI toolkit, not just a caching library - it ships vector search, semantic routing, session memory, embedding caching, and a CLI (redisvl on PyPI, v0.18.2, May 12, 2026). So why compare against it?
Because we are not benchmarking the whole toolkit. We are benchmarking redisvl.extensions.cache.llm.SemanticCache - a specific class that is open-source, Python-importable, embeddings + cosine distance threshold, Redis/Valkey-backed, and designed for app-level integration. By every architectural criterion that matters for a like-for-like comparison, it is the closest published peer to betterdb-semantic-cache.
We considered and excluded the alternatives:
- GPTCache (zilliztech): last release v0.1.44, August 1, 2024. The README states verbatim: "we no longer add support for new API or models." Benchmarking against a project dormant for almost two years would look like cherry-picking an easy target.
- Redis LangCache: a fully managed REST service on Redis Cloud, in public preview since September 2025 and bundled into the Redis Iris launch in May 2026. Benchmark numbers would be dominated by Redis Cloud network latency and would not isolate cache logic. It is the right choice if you want Redis to run everything for you; it is not a like-for-like comparison against a library you import and run locally.
- LangChain
RedisSemanticCache: wraps RedisVL internally, so benchmarking against it would double-count RedisVL's performance plus add LangChain framework overhead. @upstash/semantic-cache: TypeScript-only and hard-coupled to Upstash Vector (you cannot point it at a local Valkey instance). Not a Python peer, but it is the right TypeScript peer - we plan to benchmark@betterdb/semantic-cacheagainst it in an upcoming npm-side comparison.- vCache (UC Berkeley): research code from the ICLR 2026 paper with no PyPI release. Worth citing for its contribution to threshold selection theory; not benchmarkable as a product.
- MeanCache, SCALM: research artifacts with no published packages.
That leaves RedisVL's SemanticCache as the only actively maintained, open-source, Python-importable semantic cache library published by a major vendor. The peer is defensible.
A note on Redis's AI stack in 2026
In May 2026 Redis launched Redis Iris, a "context engine" for AI agents that bundles five components: Context Retriever, Agent Memory, Redis Data Integration (RDI), LangCache, and Redis Search. Semantic caching inside Iris is delivered by LangCache, the same managed REST API that has been in public preview since September 2025. Iris is a rebundling and rebranding of existing components, not a new product - no new standalone semantic-cache library shipped with it.
The open-source Python library RedisVL is not branded as part of Iris but remains actively maintained (latest 0.18.2, May 12, 2026). This benchmark compares BetterDB against RedisVL's SemanticCache class running on Redis 8 (Redis Open Source), which is the closest like-for-like to BetterDB's open-source surface.
For teams evaluating the managed path: LangCache is architecturally non-comparable to what we test here (managed REST service vs. locally imported library), but it is the path Redis itself now recommends for production semantic caching. If your requirement is "Redis runs everything," LangCache is what you should evaluate. If your requirement is "I import a library and run it on my own Valkey or Redis instance," RedisVL's SemanticCache and BetterDB are the two options, and the numbers below apply.
The short version
- Quality (F1): parity. BetterDB and RedisVL's
SemanticCacheland within 0.004 F1 of each other on both datasets we tested, across all configurations. They are doing the same thing well. - First-query latency: RedisVL is marginally faster. 3.44ms vs 3.87ms p50 on unique queries, within run-to-run jitter at this sample size. Both dominated by SBERT embedding compute.
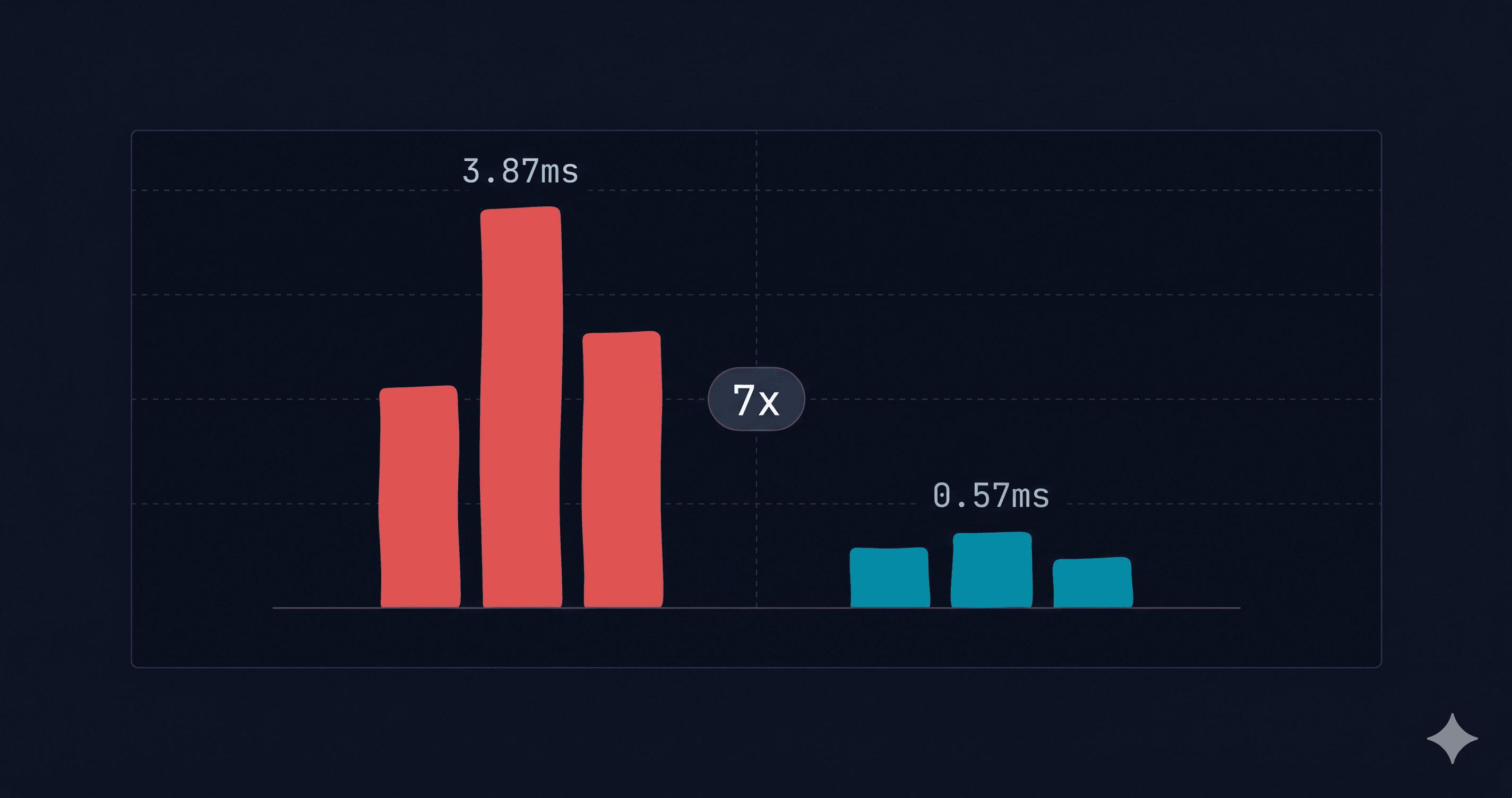
- Repeated-query latency: BetterDB is 7x faster. Our built-in embedding cache returns in ~0.57ms vs ~3.46ms for libraries that recompute embeddings each time. This matters for chatbots, agent loops, and common-question workloads.
- Valkey and Redis 8 are indistinguishable on this workload. ~0.45ms network round-trip on both. The lever for faster lookups is embedding caching, not picking the "right" Redis fork.
If you only have a minute, that is the story. The rest is methodology and footnotes.
A glossary for the impatient
Quick definitions for the terms used throughout:
- F1: a single score from 0 to 1 that balances precision and recall. Goes up when the cache makes good calls, down when it makes mistakes either way.
- Precision: of all the times the cache said "hit," what fraction were actually correct. High precision means few false positives.
- Recall: of all the genuine semantic matches that existed, what fraction did the cache catch.
- Hit rate: the fraction of queries where the cache returned anything at all. Useful as a sanity check, not a quality metric.
- False positive rate (FPR): of all queries that should have missed, what fraction wrongly got a cached response. This is the metric that matters most for user trust.
- Cosine distance / threshold: a number from 0 to 1 measuring how different two embeddings are. Lower means more similar. We swept 0.05 to 0.45.
- p50 / p95 / p99 latency: the time below which 50%, 95%, or 99% of cache lookups completed. p50 is typical, p99 is the worst-case tail.
- LLM-as-judge: when the cache is uncertain, asking a small language model whether the cached answer is good enough for the new query.
What we tested
We benchmarked three configurations of each library against two public datasets:
Datasets:
- SemBenchmarkLmArena: a public dataset of real chatbot prompts from the vCache paper (ICLR 2026; UC Berkeley, Stanford, TU Munich, ETH Zurich). Prompts are grouped into equivalence classes - prompts that should share a cached response. This represents typical AI-app workload where reuse opportunities actually exist.
- PAWS-Wiki: the standard adversarial paraphrase test from Google Research. Sentence pairs that share most of their words but mean different things - "flights from NY to FL" vs "flights from FL to NY". If a cache cannot tell these apart, it will leak wrong answers in production.
We ran 5,000 pairs per dataset multiple times, swept nine cosine distance thresholds from 0.05 (strict) to 0.45 (loose), and standardized on sentence-transformers/all-MiniLM-L6-v2 as the embedding model across every adapter so the comparison measures cache logic, not embedding choice.
We picked a generic open-source embedding model on purpose. Redis ships a domain-specific model called redis/langcache-embed-v3-small (384-dim sentence-transformers backbone, finetuned on ~8M paraphrase pairs, last updated December 2025) that is purpose-built for semantic caching workloads. Using it would have flattered RedisVL's numbers without telling us anything about cache logic. A future benchmark will test specialized embeddings on both sides.
Configurations:
- Bare: cosine distance only, no library features beyond the default lookup
- Local: every quality feature each library ships natively (rerankers, evaluators, filters - no external API calls)
- Full: adds an LLM-as-judge layer using gpt-4o-mini on borderline cases
(We picked gpt-4o-mini because it was the cost-effective default when we started the benchmark. If you reproduce this in late 2026, GPT-4.1 nano or GPT-5 nano are cheaper alternatives at $0.10 and $0.05 per 1M input tokens respectively, versus gpt-4o-mini's $0.15. The judge logic does not depend on model choice.)
Quality: F1 across both datasets
Peak F1 from the 5,000-pair sweep:
SemBenchmarkLmArena (realistic chatbot workload):
| Mode | BetterDB | RedisVL |
|---|---|---|
| Bare | 0.7178 (@0.35) | 0.7219 (@0.30) |
| Local | 0.7224 (@0.30) | 0.7226 (@0.35) |
| Full | 0.7216 (@0.30) | 0.7238 (@0.35) |
PAWS-Wiki (adversarial paraphrases):
| Mode | BetterDB | RedisVL |
|---|---|---|
| Bare | 0.6103 (@0.45) | 0.6100 (@0.40) |
| Local | 0.6101 (@0.35) | 0.6100 (@0.40) |
| Full | 0.6103 (@0.45) | 0.6100 (@0.40) |
The largest gap anywhere is 0.004 F1. That is well within statistical noise at this sample size. Both libraries are doing the same thing with the same embedding model, and the F1 numbers confirm it. There is no meaningful quality difference between them at default configurations.
What the LLM-judge actually does (and does not do)
The "Full" mode adds an LLM-as-judge gate on borderline matches. We expected it to move PAWS numbers - if cosine distance cannot distinguish "flights from NY to FL" from "flights from FL to NY," surely gpt-4o-mini can. The numbers say it does not, and the reason is interesting.
The judge only fires when the cosine distance falls within 0.05 of the configured threshold (the "uncertainty band"). On PAWS at threshold 0.15, that band catches about 6 pairs out of 5,000. Most PAWS pairs cluster very close to threshold but just outside the band, so they get accepted before the judge ever sees them.
When the judge does fire, it works - we logged the verdicts. It correctly rejected the dog/handler swap ("Once the handler is with the subject, the dog is rewarded" vs "Once the dog leader is with the subject, the dog is released"). It correctly accepted the Nokasippi River paraphrases. But on the few it did see, gpt-4o-mini also accepted "weighted bulb and a pan for weights" as equivalent to "weighted light bulb and a frying pan for weights" - which is clearly wrong. The judge helps, but it is not a magic bullet, and it does not fire often enough at default settings to move aggregate F1.
This is the kind of finding you only get from benchmarking yourself. Widening the uncertainty band would catch more pairs but cost more in API calls. That tradeoff is now something we can tune deliberately rather than guess at.
PAWS is a wall for everyone
Every adapter on PAWS-Wiki plateaus at ~0.61 F1 with false positive rate near 1.0. This is not a BetterDB limitation or a RedisVL limitation - it is a fundamental property of cosine-distance embedding caches on adversarial paraphrases.
all-MiniLM-L6-v2 cannot distinguish "Captain was hulked in 1739, and eventually broken up in 1762" from "Captain was broken in 1739, and eventually rolled up in 1762." The embeddings are nearly identical. No threshold setting recovers signal that the embedding does not capture.
This is the kind of failure mode that disappears when vendors only publish benchmarks on friendly data. We included PAWS specifically so the limitations are visible. If you cache embeddings of user prompts and serve cached responses for similar embeddings, you will eventually serve wrong answers on lexically-similar-but-semantically-different queries. Plan for it.
Latency: where it gets interesting
We profiled each adapter under controlled conditions: 200 measured queries per configuration, after 50 warm-up rounds, in isolated processes to avoid cross-contamination.
| Adapter | p50 (ms) | p95 (ms) | p99 (ms) | Embedding (ms) | Network (ms) |
|---|---|---|---|---|---|
| BetterDB on Valkey (unique queries) | 3.87 | 4.80 | 5.64 | 3.09 | 0.92 |
| BetterDB on Valkey (cycling queries) | 0.57 | 0.85 | 1.11 | 0.00 | 0.61 |
| RedisVL on Redis 8.6.3 (native API) | 3.44 | 3.87 | 4.40 | 3.03 | 0.45 |
Three things to read out of this table.
On unique queries: RedisVL is marginally faster
BetterDB at 3.87ms, RedisVL at 3.44ms. RedisVL is ~12% faster on unique queries, within run-to-run jitter at this sample size. If you are picking between the two on first-query latency alone, the difference is unlikely to matter in production where embedding compute dominates.
On repeated queries: BetterDB is 7x faster
BetterDB stores prompt embeddings in Valkey keyed by SHA256 of the prompt text. When the same prompt appears again, it returns the cached vector in ~0.57ms (one Valkey GET) instead of recomputing the SBERT embedding (~3ms). That is the 7x speedup in the cycling row.
RedisVL's SemanticCache has no equivalent feature. Every query recomputes the embedding from scratch, even if you sent the same prompt three seconds ago.
This matters in real workloads:
- Chatbots where users ask similar questions repeatedly
- AI agents that retry tool calls or recover from errors
- RAG pipelines with common query patterns
- FAQ-shaped traffic where the long tail of unique queries sits on top of a fat head of repeated ones
If your traffic has any prompt repetition at all, BetterDB will be measurably faster end-to-end, and the gap grows with hit rate.
On infrastructure: latency is the embedding model, not the backend
Look at the network column. RedisVL on Valkey takes 0.45ms per round-trip. RedisVL on Redis 8 takes 0.45ms. Identical. Both adapters spend ~3ms in SBERT embedding compute and ~0.5ms on the actual search call. The choice of vector backend - Valkey or Redis 8 - is in the noise.
This is worth saying clearly: if you are picking a vector store for semantic caching, latency should not be the deciding factor. The dominant cost is the embedding model you choose. If you want faster lookups, the lever is embedding caching (which BetterDB does and RedisVL does not), not picking the "right" Redis fork.
The practical takeaway: Valkey users are not paying a performance tax. Whatever differences exist between the two ecosystems, vector search latency is not one of them.
A note on methodology
We standardized aggressively to make the comparison fair:
- Same embedding model (
all-MiniLM-L6-v2) for every adapter - Same 5,000-pair sample, same nine thresholds
- Same dummy responses ("Answer: ") so the LLM-judge has informative content to reason over
- Isolated processes per latency measurement
- 50 warm-up rounds before measuring p50
The full harness is open source. The exact commands, datasets, thresholds, and code paths are reproducible by anyone with a few hours and a recent Valkey or Redis Stack install. If you spot something we got wrong, the issues tab is open.
What this means if you are picking a cache
Pick RedisVL's SemanticCache if:
- You are already deep in the Redis Inc. ecosystem and want their official Python library
- Your workload is mostly unique queries with little repetition
- You prefer the official Redis Inc. library
Pick Redis LangCache if:
- You want Redis to run everything - embedding, search, caching - as a managed service
- You are already on Redis Cloud and want the lowest operational overhead
- You do not need to self-host or run on Valkey
Pick BetterDB if:
- Your workload has any prompt repetition (chatbots, agents, FAQs)
- You want embedding caching out of the box without writing your own
- You want to run on Valkey rather than Redis 8 or Redis Cloud
- You want built-in observability hooks (OpenTelemetry spans, Prometheus metrics) without configuring them yourself
Pick neither if:
- You need adversarial-paraphrase resistance and your workload looks like PAWS. No cosine-distance cache will save you. You need a different architecture (cross-encoder rerank, structural parsing, or domain-specific embeddings).
What we are not telling you
A few honest limitations of this benchmark:
- We tested on
all-MiniLM-L6-v2. Numbers will shift with different embedding models. We have not yet swept across embedding choices, including Redis's ownlangcache-embed-v3-small. - We tested on 5,000 pairs. Production caches see millions. Latency at scale depends on index size, eviction policy, and memory pressure - none of which we measured here.
- We tested against RedisVL's
SemanticCacheclass specifically as the closest direct peer to BetterDB. We did not test the broader AI-gateway category, which is increasingly absorbing semantic-cache functionality:- Redis LangCache (managed REST API, public preview, part of Iris) - a managed alternative to running RedisVL yourself. Architecturally non-comparable: benchmark numbers would measure Redis Cloud network latency, not cache logic.
- Bifrost (Maxim AI, Apache 2.0) - open-source AI gateway with semantic caching on Redis/Valkey/Weaviate
- Kong AI Gateway - ships an AI Semantic Cache plugin
- Portkey - semantic caching on paid tier
- Cloudflare AI Gateway - exact-match only today, semantic on the roadmap
@upstash/semantic-cache- the only vendor-shipped TypeScript semantic-cache library; hard-coupled to Upstash Vector. This is the right peer for our upcoming npm-side benchmark of@betterdb/semantic-cache.- GPTCache - last release August 2024; maintainers state in the README that they no longer add API or model support. Effectively dormant.
- LangChain
RedisSemanticCache- a thin wrapper around RedisVL; benchmarking it would double-count RedisVL's performance
- We did not test multi-tenant cache poisoning resistance. That is a real attack vector and deserves its own benchmark.
We will keep publishing as we test more.
What is next
This is the first installment. The harness already supports more datasets and more alternatives than we used here. Coming soon:
- Self-tuning under workload shift: BetterDB's MCP-driven threshold tuning loop adapts to changing query distributions. We will benchmark it against static-threshold configurations on traces with category injection.
- npm-side benchmark:
@betterdb/semantic-cachevs@upstash/semantic-cache, the only published, vendor-shipped TypeScript semantic-cache library. Different backend coupling (Valkey vs Upstash Vector), same architectural shape. - More alternatives: LangChain
RedisSemanticCache, the LangGraph RedisSemanticCacheMiddleware, and any new entrants with meaningful adoption. - Bigger sample sizes: 50,000+ pairs, multiple embedding models, eviction policy effects.
If there is a comparison you want to see, the issues tab on the benchmark repo is the right place to ask.
All numbers in this post are reproducible. The benchmark harness, raw JSON output, and exact commands are at github.com/BetterDB-inc/monitor/packages/cache-benchmark. The datasets are public: SemBenchmarkLmArena on Hugging Face, PAWS-Wiki via Google Research.